
クラスター分析のクラスター(cluster)とは「集団」「群れ」「ぶどうの房 」を意味する言葉で、データをグループ(クラスター)に分類する分析方法です。「多変量解析」の分析方法の一つで、様々な性質のものが集まったデータを、「似ているか」「似ていないか」を基準にグループ分けしていきます。また、クラスター分析ではいくつかの計算方法が用いられますが、大きく「階層クラスター分析」と「非階層クラスター分析」の二つに分類できます。ユーザーの行動や意識パターン、属性、地域の特性、商品イメージの分類など、分析対象は様々です。

クラスター分析の種類
階層クラスター分析
階層クラスター分析は、すべてのデータの「似ているか」「似ていないか」を「距離測定方法」を使って測定し、クラスターを作っていく手法です。「距離測定方法」は、最も一般的なものが「ウォード法」、その他にも「最短距離法」「最長距離法」「重心法」などが用いられています。似ているものからクラスターを作っていくため、クラスターの数は後から決めるのが特徴です。クラスターを作っていく過程で、階層が出来上がり、樹形図(デンドログラム)として視覚化できるので、情報共有がしやすく、わかりやすいのもメリットです。
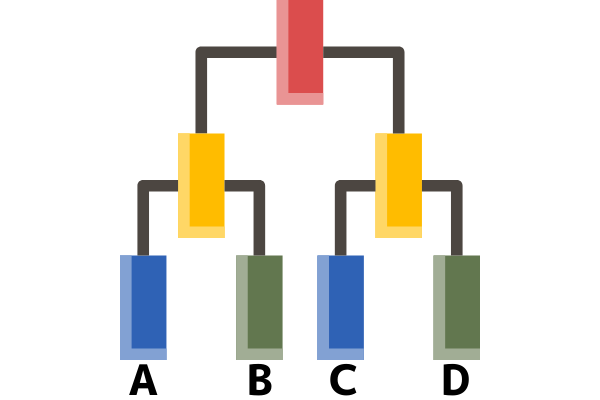
デメリットとしては、膨大なデータを扱う時は、計算不能となってしまう場合があることです。膨大なデータを分析する際には、次に紹介する「非階層クラスター分析」が有効です。
非階層クラスター分析
非階層クラスター分析は、階層クラスター分析の樹形図に見られるような階層的な構造を持たず、事前にクラスター数を決め、データを分割していく手法です。似ているデータを近くに集め、似ていないデータを遠ざけることによりクラスターを作成していきます。非階層クラスター分析に使われる「距離測定法」は「k-means法」が一般的です。まず、最終的にできるクラスターの数を決めます。それに合わせて重心がランダムに指定され、その重心からの距離を測定しデータ分割していくというアルゴリズムになっています。非階層クラスター分析のメリットは、計算数が少ないため、膨大なデータの分析に適していることです。デメリットは、最初にクラスターの数を決めなくてはならず、指定した数によって結果が多少変わる場合もあることです。
クラスター分析の役割とは
文頭でクラスター分析は「多変量解析」という統計手法の一つとお話しましたが、「多変量解析」は、商品の売り上げや、遊園地の来場者数などの結果を予測することと、教科科目を文系理系に分けるなどの要約を可能にします。クラスター分析は、そのうち「要約」的手法で、数字やアンケート回答から見える結果を、グループごとにまとめ、そこからグループごとの特徴や属性を見出すことで、マーケティングに役立てることができます。
クラスター分析の手順
まずは、分析の種類を決めます。データの種類や大きさによって「階層クラスター分析」と「非階層クラスター分析」のどちらが向いているかを判断します。そして「似ているか」「似ていないか」を決める基準を測る方法を決めます。クラスター分析で使える「距離測定方法」はいくつかあるので、どの方法を用いて分析するのか慎重に吟味しましょう。グループ分けができたら、グループの特徴や、意識、行動の分析や、各グループから様々な情報を読み取りをしましょう。
まとめ
クラスター分析は「階層クラスター分析」と「非階層クラスター分析」に分けられ、それぞれメリットとデメリットがあります。サンプルの数や種類によって使い分けをしましょう。また「非階層クラスター分析」は指定するクラスターの数により結果が異なることもあるので、何度か数を変えて分析することをおすすめします。



「どの企業に問い合わせをしたら良いか、わからない」という方へ
目的・ニーズに合致したネットリサーチ会社を、専門データベースをもとにご紹介いたします。
専門担当に相談する【お電話でのご相談】 03-5459-6616 (受付時間10:00~19:00)